Evaluate Impact
Evaluation Design
Given the likely size and complexity of an evaluation to assess not only health outcomes but also the value added by integration, programs should begin planning their impact evaluation at the earliest stages of project design. The best impact evaluations for any kind of program use a combination of evidence from formative research, implementation monitoring, and process evaluation, as well as post intervention data collection, to understand not only the magnitude of change but the mechanisms of change, as well. This is even more important when evaluating integrated programs, due to the greater number and diversity of inputs, the degree of cross-sectoral collaboration and, often, the longer time frame involved in integrated programming.
Research designs will vary depending on what is being integrated, the amount of time and funding available, the level of control the program has over implementation processes, the potential (or mandate) for dissemination of learnings from the program, and the practicality and acceptability of certain research designs (e.g., randomized trials vs. quasi-experimental vs. observational designs), among other factors. Below are several examples of research designs and examples of their appropriate use. Since true experimental designs involving random assignment to program interventions are rarely feasible with large scale full coverage programs, donors and key stakeholder groups must decide what evaluation designs are considered appropriate and sufficient to demonstrate the value of integration and the achievement of project objectives.
Tip
It is unlikely that a single type of evaluation design will tell the whole story of complex, integrated SBCC programs. Evaluation of integrated SBCC programs almost always requires a mixed methods approach. A combination of both quantitative and qualitative methods often gives the most robust picture, bringing to light direct and indirect impact pathways at multiple levels. Quantitative methods provide the most rigorous methods for measuring the magnitude and modeling the process of change at the population level, while qualitative methods provide in-depth, localized insights into synergies, unanticipated consequences, and contextual factors that help explain outcomes. The research designs that follow, therefore, are not meant to be mutually exclusive.
Evaluation Design: Randomized Controlled Trials
Randomized controlled trials (RCT), sometimes called experimental designs, randomly assign individuals or groups to receive or not receive a particular intervention, then compare outcomes among those exposed and unexposed. RCTs are generally considered to provide the strongest evidence of cause and effect, but have low external validity, meaning that they don’t generate evidence of how the intervention would work in the real world where controlled conditions are not possible. The RCT approach also builds knowledge about successful interventions by replicating studies multiple times with minor variations; this is not feasible with population-based interventions at scale. Also, programs that employ mass media as part of their intervention strategy are difficult to randomize because it is hard to prevent spillover between treatment and control locations. Integrated programs are even harder than vertical programs to study using RCTs because they typically have too many components to be systematically randomized. Facility-based interventions can sometimes be randomized—if the populations served by different facilities do not overlap—by sampling service delivery points (or providers) and randomly assigning some to implement an integrated program while others implement a vertical program, then comparing outcomes across the two groups of facilities.
– (Source: FHI360 Guidelines for Integrated Development Programs)Using a full factorial experimental design can help integrated programs determine whether an integrated design contributed to amplified or synergistic effects. In this method, participants are randomized to either: 1) a control group (no intervention), 2) a single intervention arm for each activity included in the study, or 3) a multi-intervention arm for each permutation of integration. The more components there are in the integrated strategy, the more arms of the study that must be created and randomly assigned to reflect all the possible combinations of components. FHI360 observes, “The simplest full factorial design for integrated evaluation will include four arms: one control, one for the first activity, one for the second activity, and one for the integrated activities. In such a design, if true amplification is achieved, the integrated arm(s) should show a degree of change that is greater than the sum of change among all of the arms that are not integrated.”
Program Experience
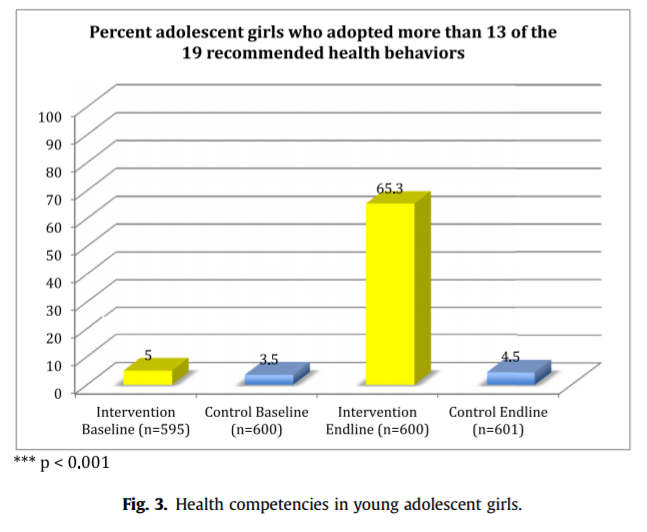 Cluster Randomized Control Design
Cluster Randomized Control Design
(When you see a Program Experience, simply click on the photo to read insights from real integrated SBCC programs.)
Evaluation Design: Quasi-Experimental Designs
Quasi-experimental designs can be used when the footprint of an intervention makes it impossible to meet RCT requirements. For example, randomly assigning communities to treatment or control conditions may result in spillover or contamination if selected communities are too close to each other or if the number of randomization units (e.g., communities or service facilities) are few, randomization may not achieve the equal distribution of background characteristics that makes the approach useful. Quasi-experimental designs purposively assign units to treatment or control with an eye toward making the two sets of communities or facilities comparable and unlikely to contaminate each other.
Program Experience
 Quasi-Experimental Design
Quasi-Experimental DesignEvaluation Design: Observational Methods
Observational methods collect data from populations of interest before and after an intervention (or after only) and use statistical techniques to control for variables that might confound an observed change in the outcome associated with program exposure. The commonly used pre-post survey approach to impact evaluation is a type of observational method. When used with population-based programs, including those that use mass media and allow stakeholders to decide for themselves whether to be exposed to the intervention, these observational designs are sometimes accused of failing to account for the fact that some people are more motivated or predisposed to be exposed in the first place and subsequently to change their behavior. Post-hoc statistical methods such as propensity score matching can be used to calculate the likelihood (propensity score) that an individual respondent is exposed or not, based on a set of background characteristics. The propensity score is then used as a control variable to compare the behavior of people at the same levels of propensity who were exposed or not exposed. This creates comparable treatment and comparison groups without pre-intervention random assignment and produces measures of impact that are similar to the results one would expect from an RCT (Kincaid & Babalola,2009)
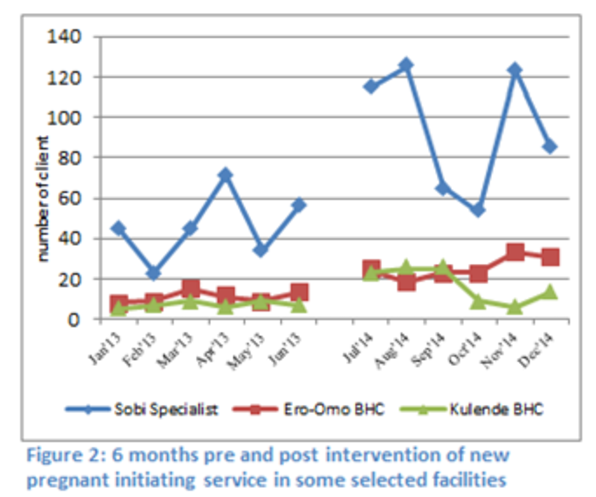
Evaluation Design: Interrupted Time Series Designs
Interrupted time series designs involve the periodic collection of psychosocial and/or behavioral data at multiple points in time prior to, during and after an intervention is implemented then using trend analysis and statistical modeling to explain changes in the outcome trends at the time the intervention begins or when new intervention components are introduced or reconfigured. Analysis of health service data often relies on this type of design. One advantage of interrupted time series designs is that they allow the use of results for making adjustments to the program, with the effects of these adjustments then assessed through additional data waves. This may be particularly desirable with integrated programs whose complex nature may require adaptations to be made. Time series designs also allow for a historical control, which decreases the number of groups required. This is beneficial for integrated programs because, with multiple interventions, the number of arms required increases dramatically. However, such designs require the measurement of as many data points before and after the intervention as possible, based on the desired resolution and anticipated time frame for observing intervention effects. This in turn may require extensive resources and also limits the applicability of this approach in the absence of sufficient pre-intervention data.” (Source: FHI360)
Evaluation Design: Panels and Longitudinal Studies
Panels and longitudinal studies collect data from the same individuals at multiple time points to track changes in knowledge, attitude, and behaviors over the course of the intervention. Data can be collected pre-intervention, at intervals during the intervention, and at intervention completion to show changes along the way.
Program Experience

Evaluation Design: Dose Response
Dose response methods can help determine whether exposure through multiple communication channels and/or to different types of messages has a cumulative effect on outcomes. By collecting detailed information on where beneficiaries engaged with the content, the type of content, and/or the frequency of exposure, you can determine how different forms or number of engagements affected program performance. While data collection may be tedious, once this detailed information is captured, there are many ways to analyze the data to determine what types of integration were most effective.
Program Experience
Evaluation Design: Social Network Analysis
Social network analysis measures the patterns and/or strength of relationships and interactions among a group of individuals (e.g. friends, colleagues), institutions (e.g. Ministries, NGOs, health facilities), or other social entities. A sociogram (e.g., a diagram of “who talks to whom” in a community or a diagram of the patterns of referrals between health facilities) allows you to visualize these connections, including the density of the network and the nature and strength of connections between nodes. Network analysis can provide quantitative, systems-level measures that reveal who the key actors might be in a neighborhood or an organization, as well as how different actors or agencies within an integrated program interact with one another.
Program Experience

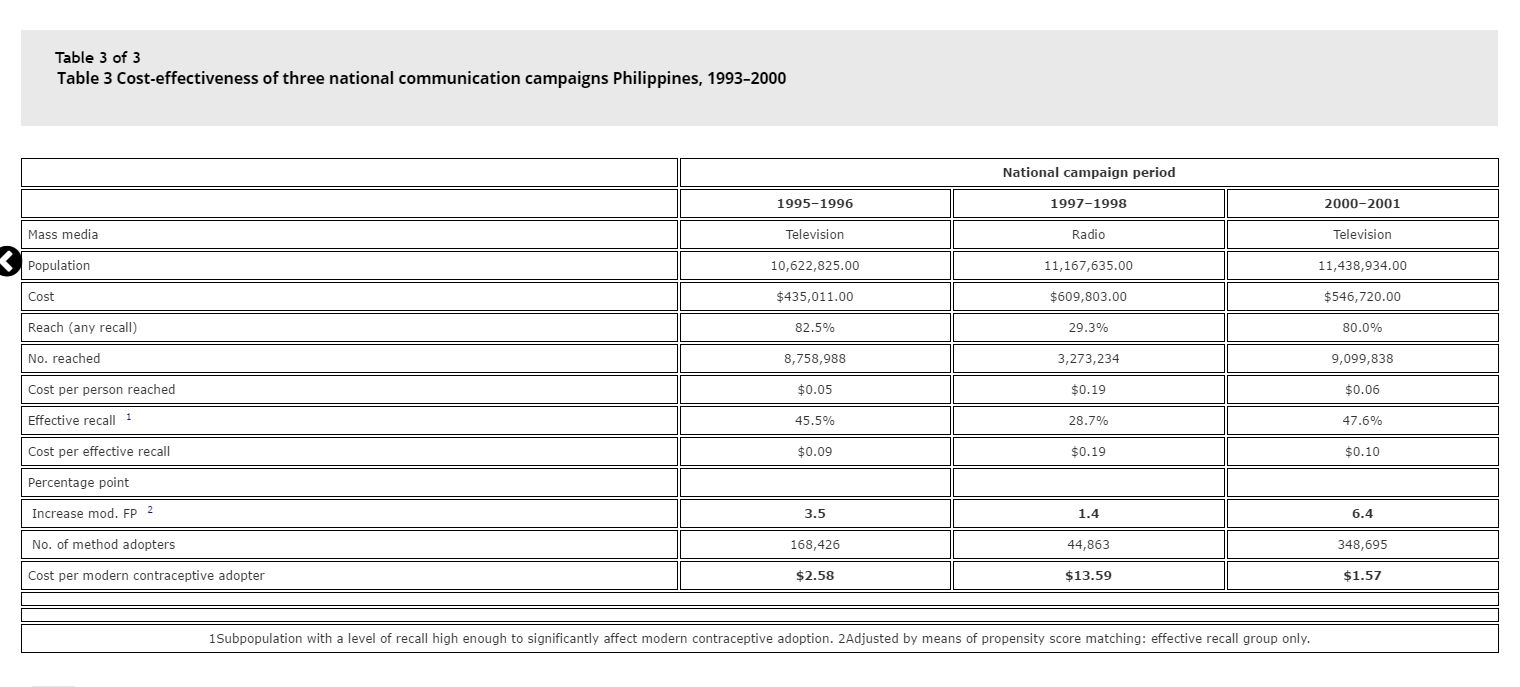
Evaluation Design: Costing and Cost Effectiveness
Costing and cost effectiveness studies help establish if integrated SBCC costs more or less than other SBCC efforts in the short, medium, and long term, and if any increased costs result in equally increased positive outcomes. It helps quantify the extent and size of operational benefits and/or negative outcomes or missed opportunities.
Program Experience
Evaluation Design: Outcome Harvesting
Outcome harvesting is particularly useful for complex, integrated programs where cause and effect are difficult to determine and outcomes cannot necessarily be predicted from the beginning. Using a consultative process involving stakeholders, outcome harvesting retrospectively identifies planned, unplanned, positive, and negative outcomes to understand the program’s role in those outcomes, and how multiple outcomes lead to system change.
Evaluation Design: Case Studies
Case studies can help identify how and why integration added value and provide insight into the change process. Their rich, holistic view helps describe the importance of context and explain the non-linear pathways and complex causal links that often feature in integrated SBCC programs, including why those causal links did or did not occur. The most significant change (MSC) technique (a type of case study design) uses a participatory methodology to systematically collect stories of impact from beneficiaries. Stakeholders then analyze the stories and select those deemed to be most significant. MSC measures changes that are difficult to quantify, such as those stemming from cultural shifts, or changes in expectations, power, or motivation. MSC is particularly useful for identifying unexpected changes and understanding program beneficiaries’ definition of success in integrated SBCC programs.
